Forecasting: structured vs unstructured
The two traditions may be merging soon, which could be good news for our collective intelligence

There’s been a lot of excitement lately about forecasting. Not the traditional time-series forecasting that you may have seen in a Stats class or Business School, but rather the less structured type that often taps into raw human intuition, which we may associate with sites like Metaculus, or the books “Superforecasting” and “Expert Political Judgement” or research on judicial forecasting. Some call this “judgemental forecasting”.
It is tempting to call one “human” forecasting and the other “computer” forecasting, but I’ve long believed that this is a bad way of dividing tasks, as anyone who believes in the potential of AI will probably agree. (For attempts to automate judgemental forecasting, check out Ought’s Ergo).
I am extremely bullish about this space for the coming decade, specifically because of how it could amplify our collective intelligence. As a layperson in almost every topic, there are so many questions that I’m in the dark about that somebody (or somebodies) could inform me on, if only (a) I could trust them to be objective and honest and, (b) they could trust me to reward them fairly. Somehow, this rarely seems to work — in the absence of clear & strong incentives, it’s just too easy for the message to deviate from what a truth-seeking principal should want. One could say that we are all suffering from a massive market failure when it comes to the sharing of probabilistic information, but I believe we are finally beginning to connect some pieces towards better solutions.
Furthermore, knowledge builds on other knowledge. Our knowledge castles could be much taller than they are today, if we didn’t spend so much effort doing the inefficient work of convincing the skeptics (who are correct to be skeptical, given the current game-theoretic equilibrium).
Without further ado, here’s how I see the two forecasting traditions:
Unstructured Forecasting
Associated with cognitive science, expert political judgement, intelligence analysis. Much effort is spent considering multiple perspectives, e.g. which reference class is most relevant, which way to break down a question makes the most sense. Sometimes funded by Defense Departments concerned with threats to national security. “Superforecasting”, “Expert Political Judgement”, judicial forecasting. Metaculus, and various prediction markets, such as Polymarket. Fewer exchangeability assumptions, which makes this approach more applicable to questions like: "How many countries will X?". Practitioners are often anonymous, and can only be trusted in proportion to their reputations (and Brier scores).
Many questions refer to binary events, such as judicial decisions and (geo)political events such as elections and wars. The output can look like a probability distribution of opinions, or an equilibrium price on the prediction market; and for individuals, a score according to scoring rules (e.g. Brier or log-score), calibration curves and/or points won or lost (sometimes redeemable for real money).
Typically suitable for predicting zero-shot questions, or those with small numbers and situations where the units are not very exchangeable, e.g. countries.
Structured (Time Series) Forecasting
Fully-automated forecasts that don't depend on human input (i.e. pure number-crunching), typically developed by people who are trained in Statistics or Operations Research or have connections to a Business school (my last team at Google had all of the above), and whose algorithms have access to clearly-structured time series.
Sometimes funded by those optimizing logistics and supply chains, or utility companies trying to ensure that demand doesn’t exceed capacity. Questions like: "How many people will test positive on this date?" or "How much of resource X will we spend?" or "How many sales will we have this year?"
Practitioners stereotypically plug in off-the-shelf methods (e.g. Autoregressive models, Kalman Filters) and run cross-validation to decide which model and parameter values to go with. They may be seen at Makridakis Competitions or the INFORMS conference. Output typically looks like prediction cones and (aggregated) loss functions over different k-folds.
Typically suitable for predicting large numbers of highly exchangeable units.
One way to think about the difference is that forecasting is always about extrapolation. In structured forecasting, you already have a dataset and you're merely extrapolating it in the time dimension (towards the future). In the unstructured case, you're extrapolating into the future AND you don't have a clear baseline. Zero-shot.
From Lustick & Tetlock (2020) – The simulation manifesto: The limits of brute-force empiricism in geopolitical forecasting:
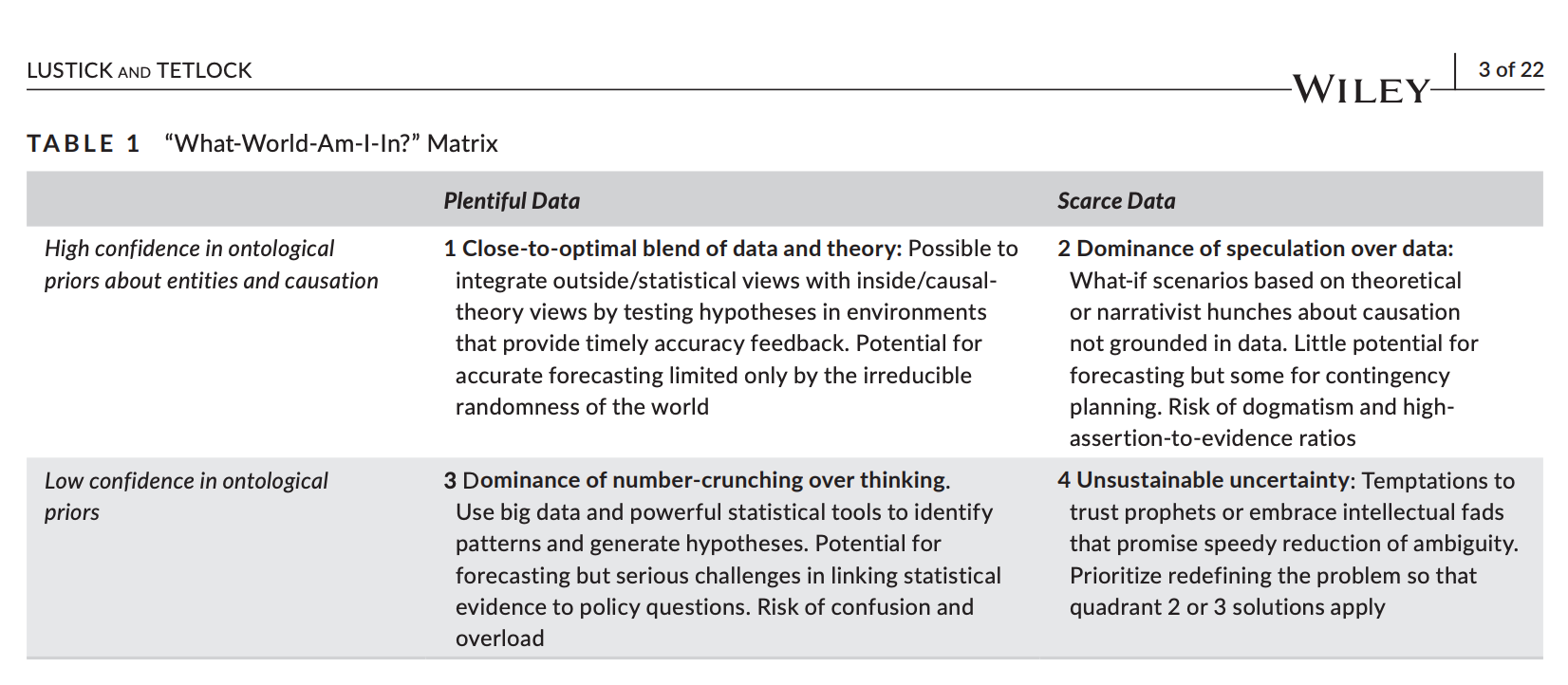
As an example, imagine you're a doctor and you see a patient with a knee meningioma, whose aggressiveness you're trying to estimate. This situation seems to be completely unprecedented. Should you treat it like an average knee tumor (which are mostly sarcomas), or like an average meningioma (which are mostly brain tumors)? This is an example of a reference class problem, for which we tend to rely on human expertise (Quadrant #2).
Clearly there’s a lot of potential for hybrid approaches here.
At the level of ensembles, we can be treated as exchangeable. But from close up, we are all individuals. So one direction is to customize individual-level forecasts to better inform the collective-level forecast. Another is that we can break down the fuzzy problem into parts, and figure out which parts are amenable to automated forecasts.
One step in this direction is the development of meta-scientific tools — predict which problems benefit a lot from human attention vs which ones are amenable to automation.
If you are as excited as I am about this stuff, consider subscribing to the Forecasting Newsletter.